學習內容總覽
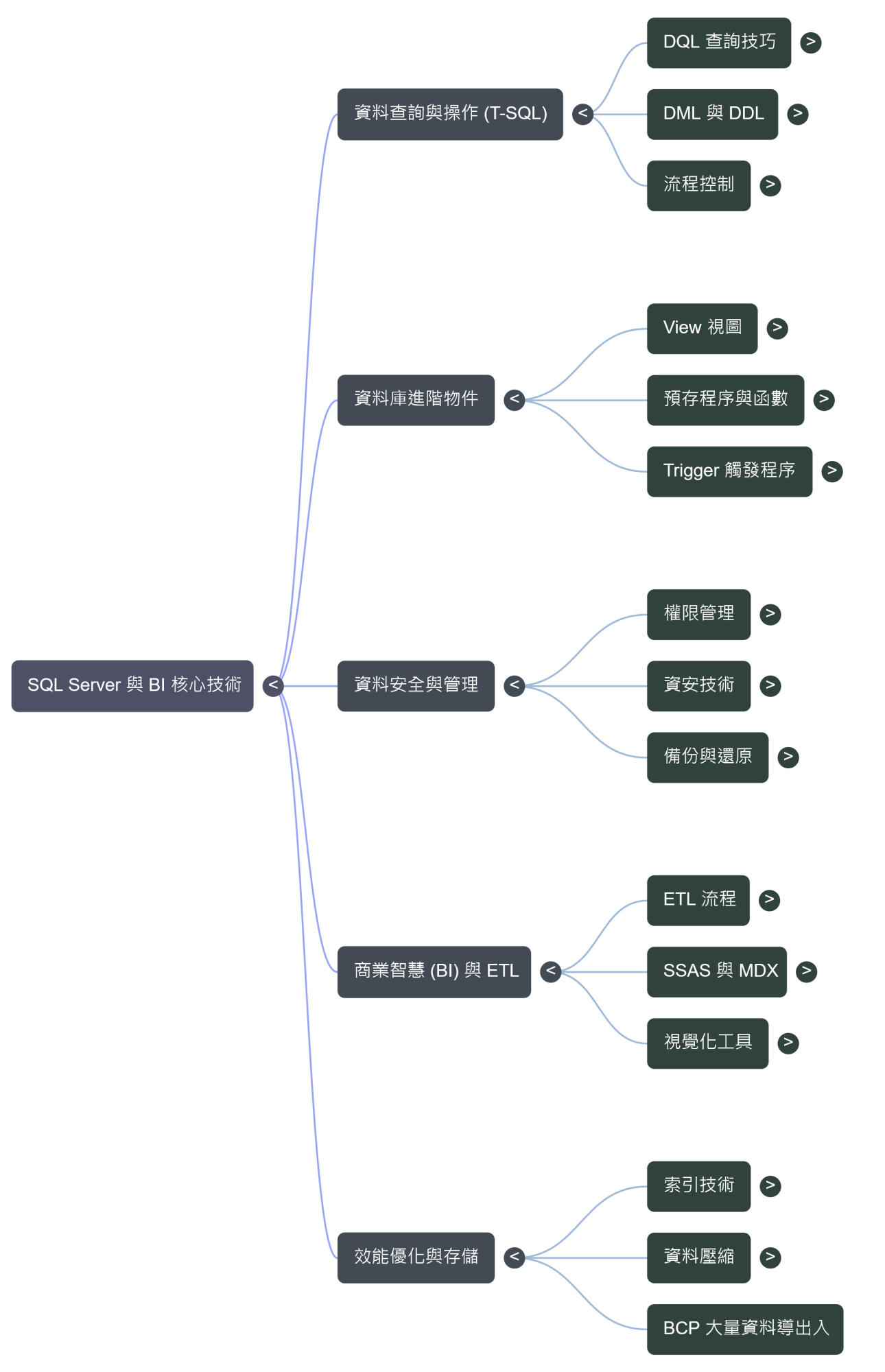
學習內容一:SQL Server
- 核心開發基石:T-SQL 語法精要與邏輯控制
- 進階查詢結構:複雜資料處理與分頁演算法
- 邏輯封裝與模組化開發:視圖、函數與預存程序
- 資料工程核心:ETL 流程與語意層架構
- 多維度分析應用:SSAS Cube 與 MDX 查詢技術
- 資料安全與管理:權限架構與備份策略
- 效能優化與存取實務:索引、壓縮與觸發程序
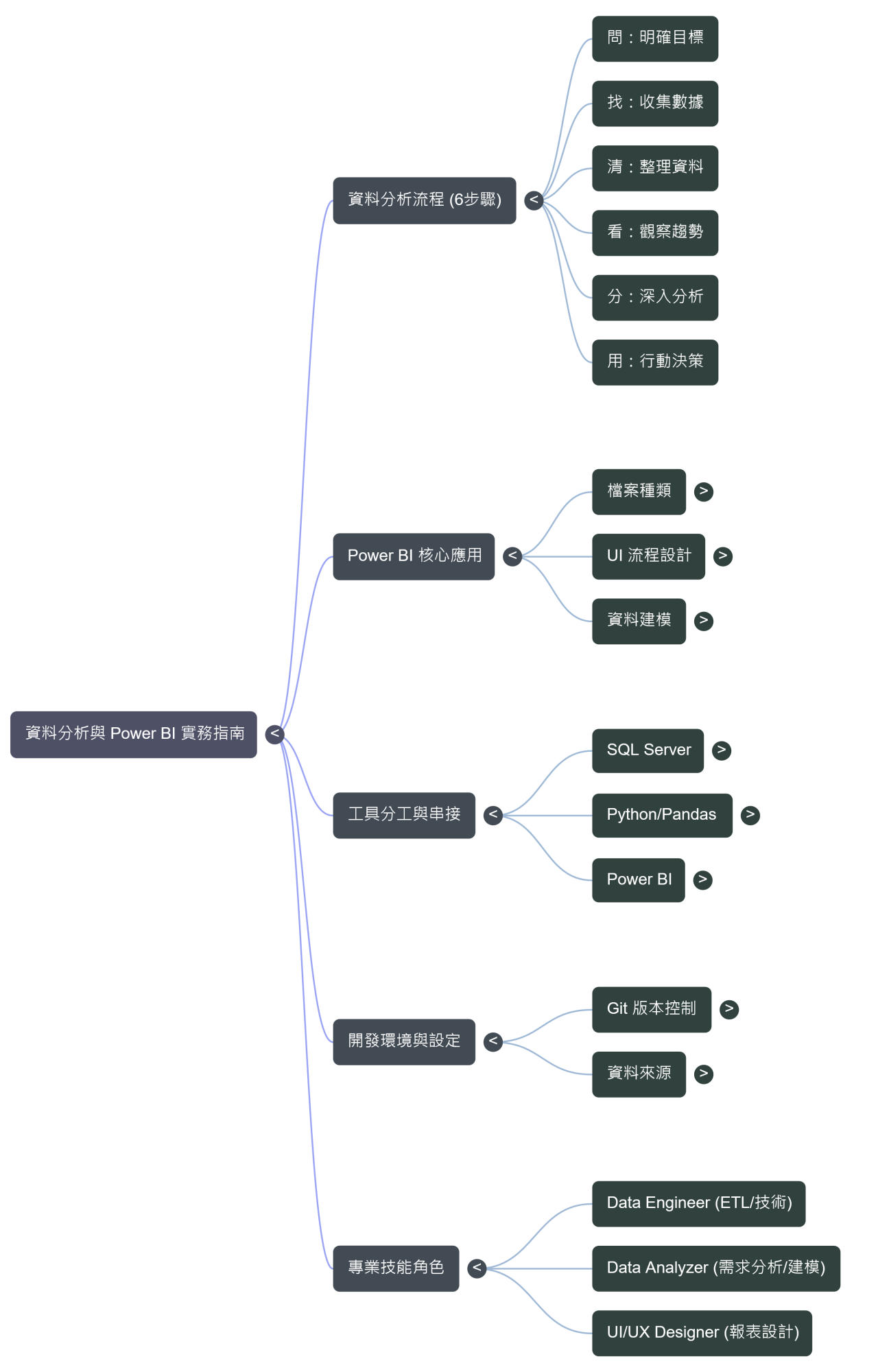
學習內容二、資料分析
SQL Server 心智圖
學習內容一:學習履歷-SQL Server
主題:SQL Server 與商業智慧開發:從資料工程到多維度分析的實務指南
作為一名資深企業資料架構師,我深知在生產環境中,程式碼的優劣不僅影響當下的執行效率,更決定了系統長期的維護成本與擴展性。本指南結合 T-SQL 邏輯精要、ETL 工程實務與 SSAS 多維度模型設計,旨在為開發者提供一套具備架構高度且可立即落地實作的技術框架。
1. 核心開發基石:T-SQL 語法精要與邏輯控制
T-SQL 是資料庫開發的靈魂。在高併發與大數據的場景下,精確的邏輯控制是確保資料一致性與效能的唯一手段。
變數管理與系統變數應用
在複雜的 Stored Procedure 中,變數賦值方式的選擇至關重要:
條件判斷與流程控制深度分析
針對邏輯分支,應根據複雜度選擇最適工具。注意 IIF 為 SQL 2012+ 引入的語法。
| 特性 / 項目 | IF...ELSE | IIF | CASE |
|---|---|---|---|
| 語法類型 | 流程控制語句 | 內建純量函數 | 運算式 (Expression) |
| 使用位置 | 批次、預存程序、觸發程序 | SELECT, WHERE 等運算式處 | SELECT, WHERE, ORDER BY (最靈活) |
| 效能 | 控制執行路徑,非資料運算 | 內部轉為 CASE,效能良好 | 效能優異,優化器深度支援 |
| 版本要求 | 所有版本 | SQL Server 2012+ | 所有版本 |
實戰範例:多層巢狀判斷
架構師必須考慮邏輯的可讀性。以下為針對產品定價的邏輯封裝範例:
自動編號機制之權衡
使用 IDENTITY(1,1) 時,必須預防「號碼用盡」與「跳號」問題。在進行大量資料遷移時,若需手動指定 ID,需開啟 SET IDENTITY_INSERT [Table] ON,並在作業結束後立即關閉。
T-SQL 的邏輯控制能力是開發的起點,而面對海量資料時,進階查詢結構與窗口函數則是提升效能的關鍵。
2. 進階查詢結構:複雜資料處理與分頁演算法
在現代商業智慧應用中,我們經常需要處理排名、移動平均或複雜的分頁需求,這要求開發者精通視窗函數與 CTE。
CTE (Common Table Expression) 之戰略優勢
CTE 不僅是「臨時性的 View」,更是優化程式碼結構的利器,尤其在處理遞迴查詢或多層邏輯時,其可讀性遠高於子查詢。
分頁查詢技術的演進
從早期的 TOP 配合 NOT IN 或 ROW_NUMBER(),到現代高效能應用程式的首選 OFFSET...FETCH:
統計與視窗函數應用
當查詢邏輯足以重用時,應將其封裝進視圖、函數或預存程序中,以實現模組化。
3. 邏輯封裝與模組化開發:視圖、函數與預存程序
視圖 (View) 的多重價值
視圖主要用於隱藏複雜度與權限管控。架構師應善用 WITH SCHEMABINDING,這不僅能防止底層表結構被意外異動,更是建立「索引化視圖」的前提。
預存程序 (SP) 與函數 (Function) 之深度對抗
| 特性 | 預存程序 (Stored Procedure) | 函數 (Function) |
|---|---|---|
| 執行方式 | 獨立執行 (EXEC) | 可嵌入 SELECT 語句中 |
| 資料異動 | 支援 INSERT / UPDATE / DELETE | 原則上僅能查詢,不可異動資料 |
| 傳回值 | 多個輸出參數 + 一個整數回傳值 | 必須傳回指定型別或 Table |
| 效能 | 編譯後執行,效能最優 | 純量函數在 SELECT 中可能導致效能瓶頸 |
實戰範例:自定義訂單號碼函數
以下為產出 yyyyMMdd + 6 位流水號的邏輯實作:
暫存物件選型之建築法則
4. 資料工程核心:ETL 流程與語意層架構
ETL 框架與業務邏輯實務
在 Transform (轉換) 階段,我們利用 View 將原始資料轉化為分析屬性。
視圖作為 SSAS 的語意抽象層
架構師不應讓 SSAS 直接連接物理表。使用 View 作為介面的四大優勢:
高效能資料交換 (bcp)
對於跨伺服器大量搬運,bcp 是唯一選擇。
5. 多維度分析應用:SSAS Cube 與 MDX 查詢技術
MDX 核心概念:Tuple 與 Set
時間序列與佔比分析
MDX 的強項在於複雜的时间偏移計算:
排序與排名實務 (DESC vs. BDESC)
在進行 Top-N 分析時,架構師必須理解 BDESC 的價值。
6. 資料安全與管理:權限架構與備份策略
行級安全性 (RLS) 實踐
透過 RLS,不同部門的經理查詢同一張表卻能看到不同結果。
災難復原矩陣
根據業務容忍度選取復原模式:
7. 效能優化與存取實務:索引、壓縮與觸發程序
儲存優化:傳統索引 vs. CCSI
在高階分析中,叢集資料行存放區索引 (CCSI) 是效能的分水嶺。
觸發程序 (Trigger):隱性效能殺手
Trigger 的運算與原始交易同步執行,必須極其輕量。
結論
一名卓越的資料架構師必須從 T-SQL 的邏輯精準度出發,透過封裝降低維護成本,利用 ETL 與 View 穩定語意層,最後輔以索引優化與嚴謹的備份機制,方能建構出支撐企業決策的商業智慧堡壘。
資料分析心智圖
學習內容二、學習履歷-資料分析
主題:數據分析實戰全書:從 Git 版本控管到 Power BI 商業決策構建
1. 數據分析的核心思維與標準化流程
在現代商業環境中,數據已成為企業最核心的戰略資產。然而,原始數據本身並不具備商業價值,唯有透過「標準化分析流程」才能將其轉化為可執行的決策。建立一套可重複、可驗證的框架,不僅能提升決策的精準度,更能降低跨部門溝通的技術門檻。
數據分析六大必要步驟:問、找、清、看、分、用
資深分析顧問深知,專案失敗往往不是因為技術不足,而是因為缺乏問題意識。我們遵循「問、找、清、看、分、用」六大口訣,將分析邏輯標準化:
| 步驟 | 定義與目標 | 書店銷售分析案例應用 | 具體產出 |
|---|---|---|---|
| 1. 問(問問題) | 明確分析目標,確保問題可被數據量化。 | 週末的銷售額是否確實比平日高? | 商業問題定義書 |
| 2. 找(找資料) | 識別並收集相關的原始記錄。 | 提取上個月每日銷售金額、日期與星期紀錄。 | 原始資料集 (Raw Data) |
| 3. 清(清資料) | 修正錯誤、處理缺漏值與統一格式。 | 補足漏填的銷售額,統一星期的寫法。 | 乾淨資料集 (Cleaned Data) |
| 4. 看(看資料) | 透過基礎彙總與視覺化觀察初步趨勢。 | 計算發現週末平均銷售(5,800元)高於平日(3,200元)。 | 初步觀察報告 / 長條圖 |
| 5. 分(分析原因) | 深度挖掘現象背後的潛在商業訊息。 | 發現週六下午的「親子說故事時間」有效帶動人流。 | 洞察假設驗證 |
| 6. 用(做決定) | 轉化為具體的行動建議與決策建議。 | 建議週日試辦活動,並針對平日推出優惠。 | 商業建議計畫書 |
2. 開發環境配置與版本控制基礎:Git
對於數據架構師而言,版本控制 (Version Control) 是專案開發的基礎建設,而非額外工作。它確保了程式碼與配置變更的「可追蹤性 (Traceability)」,在多人協作環境下防止檔案衝突,並為專案提供了隨時回溯的「安全網」。
Git 全域配置與初始化規範
在開始任何分析前,必須建立標準化的身分識別與環境過濾機制:
專案啟動工作流 (Project Initialization)
設定忽略檔 (.gitignore) 的「So What」價值: 忽略檔的核心價值在於「專案整潔」與「資安防護」。對於 BI 專案,應嚴禁將包含資料庫連線字串、API 金鑰或敏感原始資料的檔案推送到公共倉庫。良好的環境配置是後續 ETL 與資料建模穩定執行的基石。
3. 全球數據工具生態系與雲端平台分析
當前的數據生態系呈現多元化發展,企業需根據「專業度、易用性、適用場景」三大維度進行工具選型。
主流分析工具多維度比較
| 工具名稱 | 專業度 (Professionalism) | 易用性 (Ease of Use) | 適用場景 (Scenarios) |
|---|---|---|---|
| Power BI | 中高 (強大模型能力) | 極高 (入門快) | 企業端全方位商業智慧、Microsoft 生態系。 |
| Tableau | 極高 (視覺美感極致) | 中 (學習曲線陡峭) | 高度自定義視覺化、深度探索性分析。 |
| Google Looker Studio | 低 (基礎報表為主) | 高 (Web 介面) | 電商、行銷廣告即時看板與 Google 生態整合。 |
| Fine BI | 中 (側重報表設計) | 中 (配置化操作) | 特定市場區域或傳統大中型企業固定報表。 |
雲端數據平台與服務架構分析
在雲端運算方面,Microsoft Azure 提供了最完整的一站式服務:
公開資料來源價值評估
在眾多工具中,Power BI 憑藉其低學習難度與高市佔率,成為構建企業級數據交付系統的首選。
4. Power BI 深度解析:從資料架構到視覺化設計
Power BI 不僅是繪圖工具,它更是數據的「語意層 (Semantic Layer)」。它將底層複雜的關聯式資料轉化為決策者能直觀理解的商業洞察。
檔案格式情境與管理規範
流程設計 (UI) 與《資料故事時代》精神
視覺化設計的核心在於「降低認知負擔」。我們將報表層次定義如下:
建模核心:DAX 與 DIM/FACT 架構
在後端建模時,我們強調 DIM (維度表) 與 FACT (事實表) 的星型架構。DAX 語言 是驅動指標計算的核心引擎。透過「量值 (Measures)」進行動態彙總(如 YoY 成長率),而非僅依賴「計算資料行 (Calculated Columns)」,能確保模型在處理大數據量時的運算效能與靈活性。
5. 數據交付與 ETL 現代化工程
高品質的報表源於嚴謹的數據工程。數據工程師 (DE) 負責技術端的資料交付,而數據分析師 (DA) 則負責需求挖掘,兩者間的界線在於「資料是否已準備好被分析」。
ETL 工具選型與數據治理
「原始交易明細 (Transaction-level)」的不可替代性
在模擬或準備資料時,必須反映原始層級。例如,每一筆記錄應代表一次真實的訂單交易,而非預先彙總後的日報。
紮實的後端清理是實現互動式報表的先決條件。
6. 三位一體整合應用:SQL Server、Pandas 與 Power BI
透過整合三種技術棧,我們能建立一套從資料存放至最終決策的端到端 (End-to-End) 工作流。
| 工具 | 關鍵角色 | 核心功能與分工 |
|---|---|---|
| SQL Server | 資料來源與預處理 | 存放原始交易明細,利用 GROUP BY 進行初步查詢與結構化清理,減輕下游運算壓力。 |
| Pandas (Python) | 深度統計與假設驗證 | 進行複雜的數據清洗、離群值檢測、統計檢定 (如 t-test 驗證活動影響) 與科學建模。 |
| Power BI | 語意建模與視覺化決策 | 建立 DIM/FACT 模型、DAX 計算指標、互動式報表,並發布分享洞察。 |
整合架構的商業價值 (So What)
此架構完美平衡了「大規模運算效率」與「數據展示靈活性」。SQL Server 處理海量數據的沉重負擔,Pandas 確保分析的科學性,最終透過 Power BI 轉化為直觀的決策語言。
總結: 所有的技術工具(無論是 Git 的版本追蹤、SQL 的資料提取、還是 Power BI 的互動設計)最終都必須服務於最初提出的商業問題。數據從業者的價值在於透過此「三位一體」的工作流,將零散的數字織成有意義的故事。